




 Monday, 29-06-26
Monday, 29-06-26






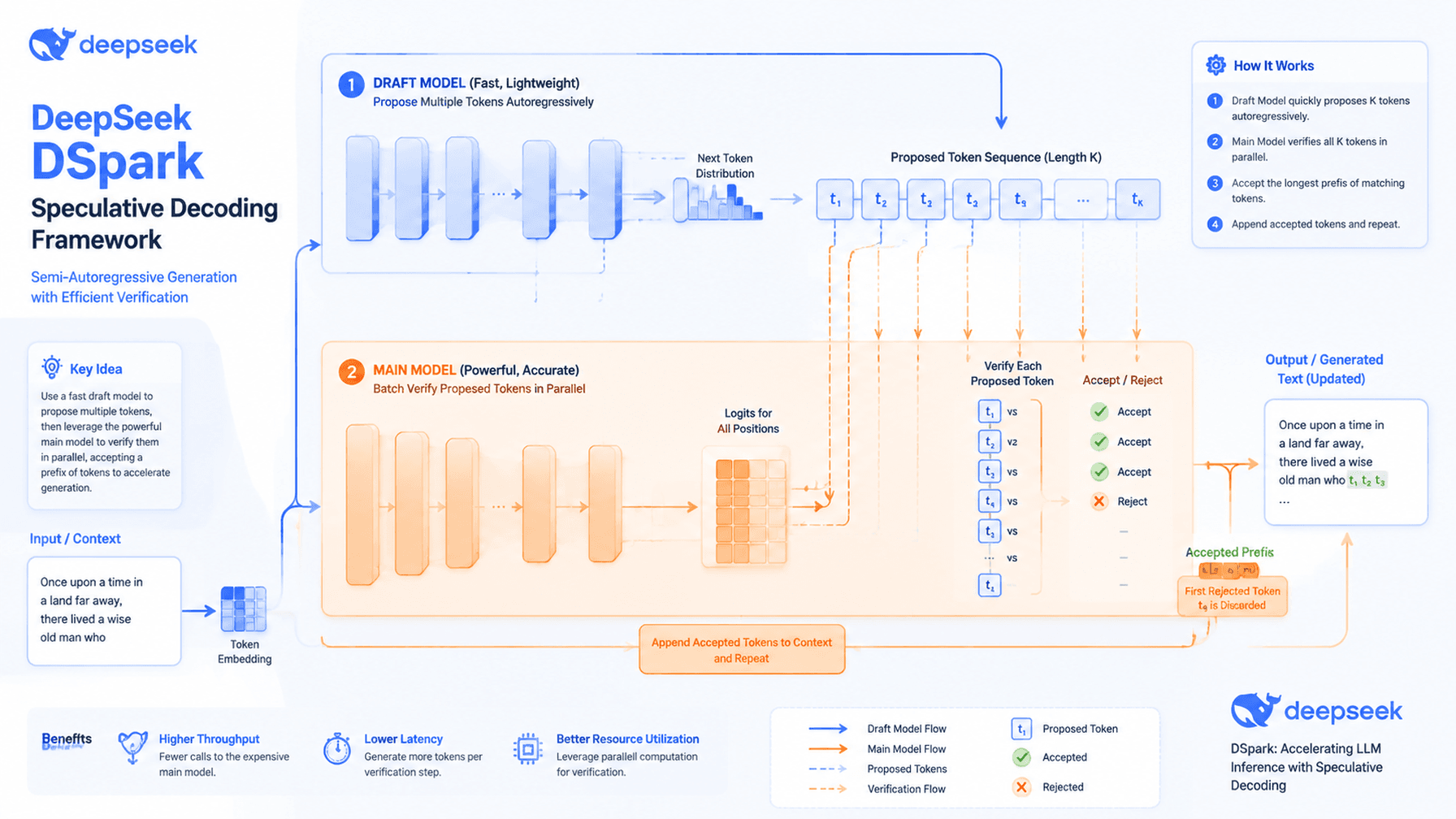
DeepSeek DSpark is not being presented as a brand new foundation model. The Hugging Face model card for DeepSeek-V4-Pro-DSpark says it is the same checkpoint with an additional speculative decoding module attached, and the DeepSpec repository describes the system as a full-stack codebase for training and evaluating draft models for speculative decoding. That makes DSpark fundamentally an inference optimization layer, not just another model release.
That distinction matters for how the market should read the launch. In a landscape where many AI announcements focus on larger parameter counts or benchmark bragging rights, DeepSeek DSpark is about throughput, latency, and serving efficiency. Industry coverage around the release described the framework as boosting generation speed by 60% to 85%, with one report framing the top-line improvement as up to 85%.
For developers and infrastructure teams, that is a more practical kind of breakthrough. Faster text generation can improve user experience, reduce server load, and lower the cost of serving high demand workloads. In other words, DeepSeek DSpark matters because it changes the economics of using a model, not only the model itself.
Why Speculative Decoding Has Become So Important
Speculative decoding has emerged as one of the most important techniques in modern LLM serving because it tries to reduce the time spent waiting for each next token. DeepSpec’s documentation shows that the workflow is built around preparing data, training a draft model, and then evaluating speculative decoding acceptance on benchmark tasks. That is a strong signal that the real bottleneck DeepSeek is targeting is inference efficiency.
The DeepSpec repository also shows that DeepSeek is treating this as a structured engineering stack, not a one off experiment. The project includes data preparation utilities, draft model implementations, training code, and evaluation scripts. It also supports multiple algorithms, including DSpark, DFlash, and Eagle3, which suggests DeepSeek is building a broader toolkit around faster generation rather than a single narrow optimization.
That strategy fits the direction of the company’s broader model ecosystem. DeepSeek’s official site and Hugging Face organization page show an active release pipeline across models, tooling, and open resources. The organization card also lists several DSpark checkpoints, including Qwen3 and Gemma4 variants, which indicates that DSpark is being distributed as a practical family of serving components rather than a one time publicity stunt.
What The DSpark Launch Tells Us About DeepSeek’s Strategy
The most interesting part of DeepSeek DSpark is that it shows where the company wants to compete. Instead of chasing the biggest model headline, DeepSeek is leaning into efficiency engineering, open distribution, and modular deployment. The Hugging Face model card for DeepSeek-V4-Pro-DSpark explicitly points users toward the DeepSpec repository for more detail, reinforcing the idea that DSpark is part of a broader systems level push.
That matters because AI competition is no longer only about raw capability. It is also about serving cost, response time, and how easily a model can be integrated into production stacks. The DeepSpec documentation shows support for direct serving through tools such as vLLM and SGLang, which makes the framework relevant to teams that need OpenAI compatible APIs and production friendly deployment patterns.
DeepSeek DSpark also fits neatly into a market where long context and higher throughput are becoming standard expectations. The DeepSeek-V4 preview materials on Hugging Face describe the V4 family as supporting one million token context and highlight architecture and optimization work aimed at improving long context efficiency. When a model family is already being optimized for scale, a speculative decoding layer like DSpark becomes a logical next step in the performance stack.
Why The Reported Speed Gain Matters For Business Users
A 60% to 85% generation speed gain is not a minor optimization. For enterprises, startups, and platform teams, that can directly affect request latency, infrastructure spending, and user retention. If a system can serve the same workload with lower inference overhead, it may be able to support more users, more concurrent sessions, or lower costs per interaction. That is why DeepSeek DSpark should be read as a commercial infrastructure move as much as a technical one.
For developers, the practical implication is straightforward. Better inference speed can make AI assistants feel more responsive, reduce waiting time in coding tools, and improve batch generation workflows for enterprise content systems. In production settings, those gains can be the difference between a tool that feels experimental and one that feels dependable. DeepSpec’s benchmark oriented workflow suggests that DeepSeek is trying to make this advantage measurable, repeatable, and portable across models.
There is also a strategic open source angle. By publishing the DeepSpec codebase and DSpark checkpoints, DeepSeek is helping shape a broader ecosystem around speculative decoding. That may increase adoption not only of DeepSeek models, but also of its serving patterns and engineering approach. In a crowded AI market, that kind of ecosystem gravity can be as valuable as a benchmark win.
What To Watch Next
The next question is whether DeepSeek DSpark becomes a one off efficiency headline or a reusable serving standard. The public release already shows the ingredients needed for wider adoption: open code, published checkpoints, serving examples, and a clear optimization target. The fact that DeepSeek-V4-Pro-DSpark is explicitly described as the same checkpoint with an added speculative decoding module suggests the company wants users to think in terms of deployable infrastructure rather than just model weights.
A second thing to watch is whether other model families adopt the same pattern. DeepSeek already lists multiple DSpark checkpoints across different base models, which points to a scalable release strategy. If the speed and cost gains hold up in real production traffic, DSpark could become one of the more influential examples of how open AI systems compete on serving efficiency rather than sheer size.
For now, the main takeaway is simple. DeepSeek DSpark is a strong sign that the race in AI is moving deeper into inference engineering. The companies that can make models faster, cheaper, and easier to serve will shape the next phase of adoption, and DeepSeek has made a clear move to be part of that competition.
Read More